KI-Modelle
KI-Modelle
Dieses Kapitel gibt einen Überblick über KI-Modelle und unterteilt sie in verschiedene Leistungsgruppen. Sie stellen die Basis für verschiedenste Tools und Services dar, von denen einige im gleichnamigen Kapitel vorgestellt werden. Die Modelle unterscheiden sich, und so wird für eigene KI-Projekte entlang der jeweiligen Anforderungen entschieden, welches Modell am besten geeignet ist. Denn die Ergebnisse von Anwendungen, die mit generativer KI arbeiten, hängen maßgeblich vom zugrunde gelegten Modell ab.
Wieso sprechen wir von Modellen?
Ein Modell ist eine Abstraktion, ein aus den Trainingsdaten "gelerntes" System von Strukturen, Regelmäßigkeiten und Wahrscheinlichkeiten. Es findet bei Sprachen keine umfassende formale Spracherlernung statt, da diese (noch) viel zu komplex ist für eine zeitnahe Verarbeitung in Dialogen. Jede Anfrage interpretiert die KI-Anwendung aufs Neue. Sie generiert auf der Basis der aus den Trainingsdaten gewonnenen Modelle die Antworten. Das verdeutlicht die Abhängigkeit von den in der Trainingsphase ausgewählten Daten.
Und selbst wenn eine generative KI-Anwendung grammatikalisch und stilistisch perfekt klingende Texte kreiert: Es bleibt eine unscharfe Annäherung aufgrund von Wahrscheinlichkeiten. Daher beobachten wir so genannte "Halluzinationen" mit inhaltlich unsinnigen Antworten.
Wie entstehen KI-Modelle?
Nimm als Beispiel an, Du willst lernen, realistische Porträts zu malen. Du kannst dafür in Hunderten von berühmten Gemälden studieren, wie darin Details wie Beleuchtung, Gesichtszüge und Mimik und Beleuchtung eingefangen wurden. In ähnlicher Weise arbeiten KI-Modelle, indem sie eine große Menge an Daten studieren. Das KI-Modell analysiert diese Trainingsdaten und erkennt Muster und Beziehungen zwischen verschiedenen Elementen. Je mehr Daten es studiert, desto besser versteht es die Feinheiten.
Handelt es sich bei den Trainingsdaten um Bilder, Zeichnungen oder Fotos von Tieren, Landschaften oder Alltagsgegenständen, kann eine KI auf der Basis des trainierten Image Generation Model Bilder oder Fotos generieren. Text versteht sie weniger – daher funktionieren Texte in KI-generierten Fotos nur selten.
Für die Code- oder Texterstellung beispielsweise werden andere KI-Modelle mithilfe von riesigen Mengen an Code- und Textdaten trainiert. Sie erkennen die Muster und Strukturen von Programmiersprachen, Satzstrukturen und Wortverwendung in menschlichen Sprachen. Je mehr Daten sie analysieren, desto besser werden diese Large Language Models (LLMs) darin, sinnvollen Code oder Text zu erzeugen.
Der Schlüssel: Transformer & Attention
Vor Veröffentlichung der so genannten Transformer in 2017 zählte die Generierung natürlicher Sprache zu den anspruchsvollsten Aufgaben – trotz bereits hochentwickelter neuronaler Netze. Transformer und Attention sind wichtige Entwicklungen für Large Language Models, um komplexe Sprachmuster zu erfassen und menschenähnlichen Text zu generieren.
Der Transformer ist ein neuronales Netzwerkmodell, das speziell für die Verarbeitung von Sequenzen entwickelt wurde. Es besteht aus mehreren Schichten von Aufmerksamkeits-Mechanismen, die dem Modell erlauben, sich auf verschiedene Teile der Eingabesequenz zu konzentrieren. Die Attention-Mechanismen sind ein Schlüsselkonzept im Transformer-Modell, denn dadurch können komplexe Zusammenhänge zwischen Wörtern in einem Text erkannt und darauf aufbauend kontextabhängige Vorhersagen getroffen werden.
Vorhergehende Konzepte basieren Wortvorhersagen ausschließlich auf der Grundlage früherer Wörter. Im Gegensatz dazu ermöglicht der Aufmerksamkeits-Mechanismus der Transformer, Wörter bidirektional vorherzusagen – also auf der Grundlage sowohl der vorherigen als auch der nachfolgenden Wörter.
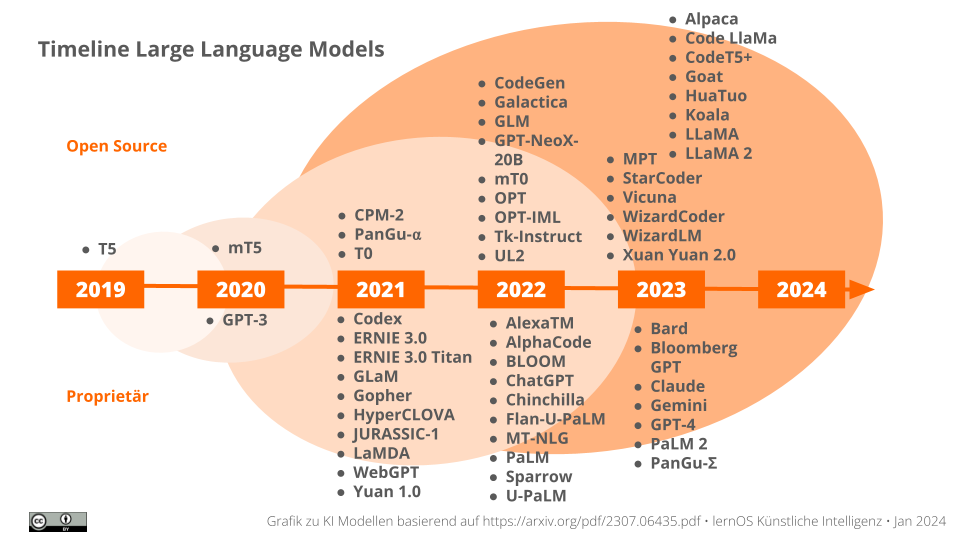
Diese Entwicklung von LLMs zeigt die obige Grafik. Wie wir sehen können, wurden die ersten modernen Modelle kurz nach der Entwicklung der Transformer vorgestellt. Die Grafik zeigt, dass es inzwischen mehr und mehr zur Entwicklung von Modellen kommt, die mit einer Open Source-Lizenz veröffentlicht werden.
Beispiele generativer KI-Modelle
Um Unterschiede zu verstehen, geben die Tabellen Kurzinfos zu verschiedenen KI-Modellen. Das ist eine Momentaufnahme, denn die KI-Modelle werden weiterentwickelt und trainiert. Daher ist die Versionsbezeichnung der jeweiligen Modelle essentiell für die qualitative Einschätzung der generierten Inhalte. Insbesondere wenn der Umfang der Trainingsdaten erheblich vergrößert wird. Zur Kurzinfo ergänzt:
- Modellgröße: Die Modellgröße ist ein wichtiger Faktor für die Leistungsfähigkeit eines Sprachmodells. KI-Anwendungen, die auf ein größeres Modell zugreifen, können komplexere Zusammenhänge verstehen und generieren. Sie sind damit vielseitiger als auf spezielle Anwendungsgebiete trainierte Modelle. Eine hohe Anzahl der Parameter machen Modelle rechnerisch teurer. In der Praxis ist zwischen Ergebnisleistung und dem dafür erforderlichen Energieverbrauch abzuwägen.
- Nutzungslizenz: Modelle mit einer Open Source-Nutzungslizenz besitzen einen veröffentlichten Quelltext. Sie können von anderen geändert und genutzt werden. Open-Source-Modelle können unter Einhaltung der Lizenzbedingungen meistens kostenfrei genutzt werden.
Modelle zur Textgenerierung / Code
KI-Modelle können eingegebene Texte (oder gesprochene Sprache) verstehen und daraufhin neue Texte generieren, die einem von Menschen geschriebenen Inhalt ähneln. Das können Sprachübersetzungen, Textverbesserungen, Chatbot-Dialoge, Stilübertragungen oder die Generierung von Inhalten wie Gliederungen, Blogbeiträgen, Artikeln, Kursfragen sein. Genauso schreiben entsprechend trainierte KIs auch Software-Code.
| Modell | Modellgröße (Mrd. Parameter), Lizenz |
|---|---|
| Gemini - Nach experimentellen Sprachmodellen konzipierte Google dieses Modell von Grund auf multimodal. Es kann verschiedene Arten von Informationen – Text, Code, Bild, Audio oder Video – interpretieren. Das Modell wird auf anspruchsvolle logische Aufgaben, Übersetzungen und zur Generierung natürlicher Sprache trainiert. | 8.000, closed source |
| GPT - Die Abkürzung des bekanntesten Modells steht für Generative Pre-trained Transformer. Anbieter OpenAI trainiert das Modell für Dialoge, Textgenerierung oder auch Code-Entwicklung. Die Eingabe verarbeitet Text, Sprache oder Bildmaterial. Das Sprachmodell wird iterativ durch Verstärkungslernen mit menschlichem Feedback (Reinforcement Learning from Human Feedback, RLHF) verbessert. | 1.000 (GPT-4), closed source |
| LEAM - Die Abkürzung steht für Large European AI Models, deren Entwicklung berücksichtigt insbesondere europäische Werteinstellungen und hohe Anforderungen in Bezug auf Datenschutz, Transparenz und Voreingenommenheit. Gleichzeitig soll die Gestaltung des Trainings von KI-Modellen nachhaltiger werden. | k.A., ? |
| LeoLM - Die Abkürzung steht für Linguistically Enhanced Open Language Model, das erste offen und kommerziell verfügbare deutsche Basis-Sprachmodell. Es basiert auf einer Version von LLaMA. | k.A., ? |
| LLaMA - Anbieter Meta trainiert die Modellvarianten LLaMA Chat für Dialoge sowie Code LLaMA mit code-spezifischen Datensätzen für die Softwareentwicklung. | 70 (LLaMA-2), open source |
| Luminous - Von Aleph Alpha ist ein in fünf europäischen Sprachen trainiertes Sprachmodell: Deutsch, Englisch, Französisch, Italienisch und Spanisch. Die Eingabe zur Textentwicklung kann mit Text oder kombiniert mit Bildern erfolgen. | 200, closed source |
| Whisper - Universell einsetzbares Modell von Open AI, das die mehrsprachige Erkennung von Sprache in Audiodateien bietet und das Ergebnis als Text oder übersetzten Text ausgibt. | k.A., open source |
Modelle zur Bilderzeugung
KI-Modelle können auf der Basis von Texteingaben (zum Teil auch Bilddateien) neue Bilder erzeugen, die realen Objekten oder Szenen ähneln. Dazu gehören Aufgaben wie Bildsynthese, Stilübertragung, oder Bildverbesserung (Superresolution). Tools zur Verbesserung von Fotos oder Bewegtbilder werden Upscaler genannt.
Sie nutzen die so genannte Diffusion, was die Verteilung von Partikeln im Raum beschreibt. Diesem ähnlich verändert die KI einzelne Pixel in einem Bild fortlaufend und in Interaktion miteinander basierend auf gelernten Informationen, um neue Inhalte zu erzeugen.
| Modell | Open Source |
|---|---|
| DALL•E - Das Modell von Open AI versteht Beschreibungen in natürlicher Sprache, um daraufhin detaillierte und real wirkende Fotos und Kunstwerke zu erstellen. Das Modell wird in vielen Anwendungen als Basis genutzt. | closed source |
| Firefly Image - Das Modell zur Bildgenerierung von Adobe setzt auf lizenzierte Fotos der eigenen Bilddatenbank und gemeinfreies Bildmaterial. Für die Version 2 ist das individuelle Trainieren mit eigenen Werken in der Entwicklung. Das Modell generiert ähnlich hochwertige Bilder wie DALL•E. | closed source |
| LoRA Stable Diffusion - Die Abkürzung steht für Learn On Reconstruction and Attention. Das Modell ist eine Kombination von Algorithmen für das Fine-Tuning von Bildern und Bildstil-Training. Nach Training mit ausgewählten Bildern erkennt die KI einen bestimmten Stil, um diesen dann auf andere Bilddaten anzuwenden. | open source |
| Midourney - Das Modell des Forschungslabors Midjourney generiert hochwertige, hyperrealistische Bilder auf der Grundlage von Texteingaben. Es gibt künstlerische Stile sowie kreative Filter zur Anpassung erzeugter Bilder. Das Modell wird für seine einzigartige Verknüpfung von technischer Leistungsfähigkeit, künstlerischem Flair und einer lebendigen Community geschätzt. | closed source |
| OpenJourney - OpenJourney ist ein von PromptHero entwickeltes kostenloses, quelloffenes Text-Bild-Modell. Es kann KI-Kunst im Stil von Midjourney generieren. HuggingFace. Die Benutzer bevorzugen Openjourney wegen seiner Fähigkeit, mit minimalen Eingaben beeindruckende Bilder zu erzeugen, und wegen seiner Eignung als Basismodell für die Feinabstimmung. | open source |
LAION wird Dir in diesem Zusammenhang begegnen: Die Abkürzung steht für Large-scale Artificial Intelligence Open Network. Es stellt den größten öffentlich zugänglichen Trainingsdatensatz dar.
Modelle zu Audio-/Videogenerierung
Das Kapitel soll Dir einen Einstieg in das Themenfeld KI-Modelle geben. Neben den in den Fokus gestellten Modellen zur Text- und Bildgenerierung gibt es weitere Modelle, mit denen natürlich wirkende Sprache erzeugt werden kann. Anwendungen für künstlich erzeugte Sprachausgaben sind schon lange in Benutzung, die Ergebnisse klingen selten wie eine Sprechstimme.
Die neuen KI-Modelle bringen die Spachsynthese auf ein neues Niveau. Andere Modelle können dafür genutzt werden, Musik zu komponieren. Auf Bewegtbild trainierte Modelle erzeugen flüssig ablaufende Videos mit hoher Qualität.
Auf der Basis dieser Modelle ist es möglich, Deepfakes zu generieren.
Modelle in Bewegung
Da die Modelle die Basis für die Leistungsfähigkeit einer KI-Anwendung darstellen, wird darin viel Entwicklung investiert. Dieses Kapitel ist daher nur eine Momentaufnahme. Bleib dran an den Entwicklungen mit den Blogs von Andrew Ng oder HuggingFace.
Hinweis: Bitte habe diese Diskussionen zu Modellen und ihren Trainingsdaten im Blick:
- Es wurden Rechtsklagen eingereicht von Kunstschaffenden gegen Stability AI oder Midjourney, weil diese urheberrechtlich geschützte Werke im Training genutzt haben.
- Softwareentwickler klagen gegen Unternehmen wie GitHub, Microsoft oder OpenAI, weil diese ihren Open-Source-Code als Trainingsdaten für die KI-Entwicklung hernehmen.